
ในวันที่ธุรกิจต้องแข่งขันด้วยข้อมูล ความเร็ว และความแม่นยำในการเข้าถึงลูกค้ามากกว่าการทำราคาหรือโปรโมชั่น คำว่า AI คือ จึงไม่ใช่แค่ Buzzword อีกต่อไป แต่กลายเป็นเครื่องมือสำคัญที่ช่วยให้แบรนด์ตัดสินใจได้ดีขึ้น เข้าใจลูกค้าได้ลึกขึ้น และวิเคราะห์แนวโน้มได้แม่นยำแบบเรียลไทม์ ซึ่งเบื้องหลังความสามารถอันชาญฉลาดของ AI เหล่านี้ ไม่ว่าจะเป็น ChatGPT คือ โมเดลภาษาที่เข้าใจคำถามได้เหมือนมนุษย์, Gemini คือ ผู้ช่วยอัจฉริยะจาก Google หรือแม้กระทั่งแพลตฟอร์มระดับองค์กรอย่าง Vertex AI คือ ระบบที่องค์กรใช้พัฒนาโมเดล AI ของตนเอง ล้วนขับเคลื่อนด้วยสิ่งที่เรียกว่า “Deep Learning”
หลายคนอาจสงสัยว่า Deep Learning คืออะไร และต่างจาก Machine Learning อย่างไร? คำตอบไม่ใช่เรื่องไกลตัว เพราะ Deep Learning ไม่ได้จำกัดอยู่แค่ในวงการเทคโนโลยี แต่แทรกซึมอยู่ในธุรกิจทุกประเภท ดังนั้น บทความนี้เราจะพาไปทำความรู้จักว่า Deep Learning AI คืออะไร พร้อมทั้งอธิบายหลักการทำงาน ประเภทของโมเดล ไปจนถึงตัวอย่างการประยุกต์ใช้จริง ที่นักธุรกิจ นักการตลาด และสายเทคโนโลยีสามารถนำไปต่อยอดได้ทันที
Deep Learning คืออะไร ?
Deep Learning คือ สาขาย่อยของ Machine Learning ซึ่งอยู่ภายใต้กรอบของเทคโนโลยีปัญญาประดิษฐ์ (Artificial Intelligence หรือ AI) โดยเป็นเทคนิคที่ใช้ โครงข่ายประสาทเทียมหลายชั้น (Deep Neural Networks) เพื่อให้คอมพิวเตอร์สามารถเรียนรู้จากข้อมูลจำนวนมาก และดึงคุณลักษณะที่ซับซ้อนออกมาได้แบบอัตโนมัติ

ด้วยความลึกของโครงข่ายที่มีจำนวนชั้นที่มาก ทำให้ Deep Learning สามารถรับรู้และวิเคราะห์ข้อมูลที่ซับซ้อนอย่าง ภาพ เสียง ข้อความ หรือภาษาธรรมชาติ (Natural Language) ได้อย่างแม่นยำ เช่น การจดจำใบหน้าในภาพถ่าย การถอดเสียงพูดเป็นข้อความ การแปลภาษาอัตโนมัติ เป็นต้น
และเพื่อให้เข้าใจมากขึ้น เดี๋ยวเราจะมาไปดูกันต่อว่า Machine Learning กับ Deep Learning แตกต่างกันอย่างไรในหัวข้อถัดไป
Deep Learning กับ Machine Learning แตกต่างกันอย่างไร ?
แม้ทั้งสองแนวคิดจะอยู่ภายใต้ร่มของ AI แต่จริงๆ แล้วมีความแตกต่างกันอย่างชัดเจนในเชิงโครงสร้าง วิธีการเรียนรู้ และการนำไปใช้งาน ดังนั้น มาเปรียบเทียบ Deep Learning vs Machine Learning กันเพิ่มเติมว่า แตกต่างกันอย่างไร
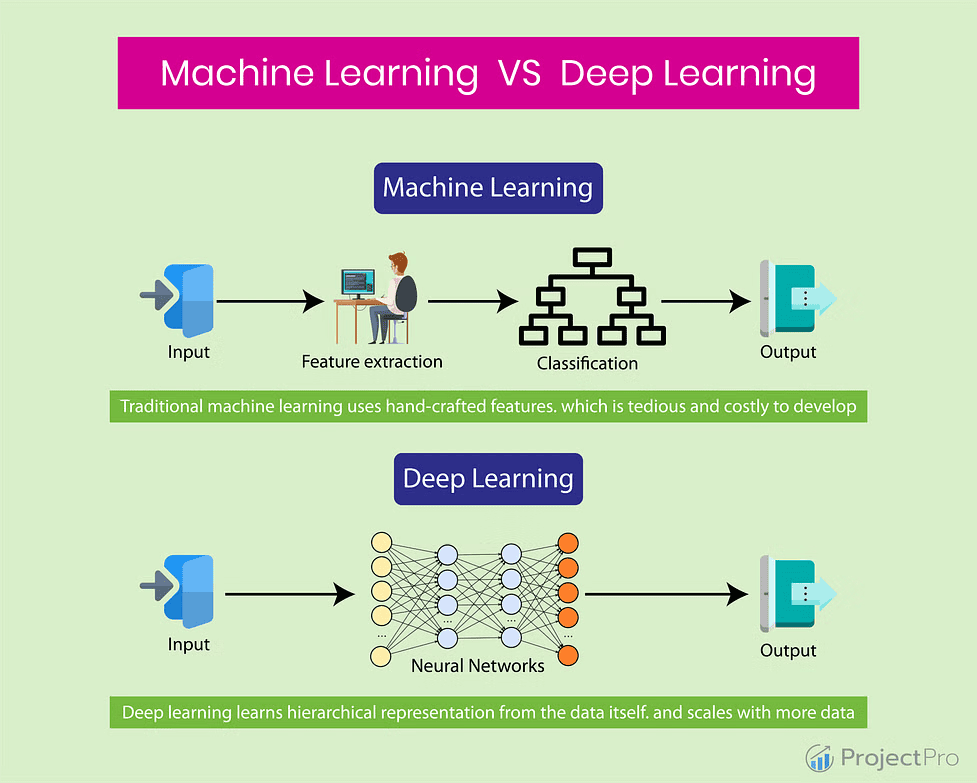
Machine Learning คืออะไร?
Machine Learning คือ กระบวนการที่ทำให้คอมพิวเตอร์สามารถเรียนรู้จากข้อมูลโดยไม่ต้องเขียนโปรแกรมแบบตายตัว แต่จะอาศัยอัลกอริธึมที่เรียนรู้จากประสบการณ์ เพื่อสร้างแบบจำลอง (Model) สำหรับการทำนายหรือจำแนกผลลัพธ์ในอนาคต
ในระบบ Machine Learning แบบดั้งเดิม นักพัฒนาจะต้อง ออกแบบ Feature (คุณลักษณะของข้อมูล) ด้วยตนเอง เช่น การเลือกค่าทางสถิติจากภาพ หรือการวิเคราะห์พฤติกรรมผู้ใช้งาน จากนั้นจึงนำเข้าโมเดลอย่าง Decision Tree, SVM หรือ Random Forest เพื่อสร้างผลลัพธ์ต่อไป แต่สิ่งสำคัญคือ Machine Learning ต้องอาศัยความเชี่ยวชาญของมนุษย์ในการออกแบบฟีเจอร์ ซึ่งหากออกแบบไม่ดี ผลลัพธ์ก็จะคลาดเคลื่อนหรือมีประสิทธิภาพต่ำ
ในทางกลับกัน Deep Learning คือ สาขาย่อยของ Machine Learning ที่ใช้ โครงข่ายประสาทเทียมหลายชั้น (Deep Neural Networks) เพื่อให้คอมพิวเตอร์สามารถเรียนรู้จากข้อมูลดิบได้โดยตรง โดยไม่ต้องมีการออกแบบ Feature ล่วงหน้า ซึ่งข้อดีคือ Deep Learning สามารถดึงคุณลักษณะเชิงลึกจากข้อมูลที่ซับซ้อนได้อย่างมีประสิทธิภาพ เช่น การแยกแยะวัตถุในภาพ (Computer Vision), การแปลภาษาอัตโนมัติ (Machine Translation), การเข้าใจภาษาธรรมชาติ (NLP) เป็นต้น
หากเปรียบเทียบในด้าน การประมวลผลข้อมูลจำนวนมาก หรือข้อมูลที่ไม่มีโครงสร้าง (Unstructured Data) เช่น ภาพ วิดีโอ เสียง ข้อความ ฯลฯ Deep Learning จะมีความสามารถเหนือกว่า แต่ Machine Learning ก็ยังคงเหมาะกับงานที่มีข้อมูลเชิงโครงสร้าง และต้องการโมเดลที่ทำงานได้เร็ว ใช้ทรัพยากรน้อย เช่น งานคัดกรองสแปม, การทำนายยอดขายเบื้องต้น เป็นต้น
สรุปเปรียบเทียบ Deep Learning vs Machine Learning
| หัวข้อเปรียบเทียบ | Machine Learning | Deep Learning |
| การสร้างฟีเจอร์ (Feature) | ต้องออกแบบด้วยมนุษย์ | ระบบเรียนรู้ฟีเจอร์เองจากข้อมูลดิบได้ |
| ความเหมาะสมกับข้อมูล | ข้อมูลเชิงโครงสร้าง (Structured) | ข้อมูลไม่มีโครงสร้าง เช่น รูป เสียง ภาษา (Unstructured) |
| ความซับซ้อนของโมเดล | ต่ำกว่า Deep Learning แต่ทำงานเร็ว | สูง ต้องการโครงข่ายหลายชั้นและเวลาฝึกสอนนาน |
| ทรัพยากรที่ใช้ | ใช้น้อยกว่า | GPU / TPU และพลังประมวลผลสูง |
ทำความเข้าใจหลักการทำงานของ Deep Learning
AI Deep Learning เป็นเทคโนโลยีที่เปลี่ยนโลกของการประมวลผลข้อมูลจากแบบเดิมที่ต้องคอยตั้งกฎให้คอมพิวเตอร์ทำงานตามคำสั่งหรือกฎที่วางไว้ มาเป็นการให้คอมพิวเตอร์เรียนรู้จากข้อมูลได้ด้วยตัวเอง ซึ่งหัวใจสำคัญของ Deep Learning คือการใช้ โครงข่ายประสาทเทียมหลายชั้น หรือที่เรียกว่า Neural Networks
มาดูกันว่า หลักการทำงานของ Deep Learning นั้นเป็นอย่างไร ตั้งแต่การทำความเข้าใจโครงสร้าง การประมวลผลในแต่ละชั้นของโมเดล ไปจนถึงการนำผลลัพธ์มาใช้งานจริง
โครงสร้างของ AI Deep Learning
หัวใจสำคัญของ Deep Learning คือ โครงข่ายประสาทเทียม (Artificial Neural Network) ซึ่งได้รับแรงบันดาลใจมาจากโครงสร้างสมองของมนุษย์ โดยประกอบด้วย 3 ส่วนหลัก ได้แก่

- Input Layer: เป็นชั้นแรกที่รับข้อมูลดิบเข้าสู่ระบบ เช่น พิกเซลของภาพ คำในประโยค ค่าต่างๆ ในชุดข้อมูล เป็นต้น
- Hidden Layers: เป็นชั้นที่อยู่ระหว่าง input และ output โดยข้อมูลจะถูกประมวลผลผ่านหลายชั้น และเรียนรู้คุณลักษณะที่ซับซ้อนขึ้นเรื่อยๆ
- Output Layer: ให้ผลลัพธ์สุดท้าย เช่น จำแนกว่าเป็นรูปแมวหรือหมา ทำนายราคาบ้าน แปลภาษา ฯลฯ
ด้วยโครงสร้างนี้เองที่ทำให้ Deep Learning สามารถดึง latent pattern จากข้อมูลได้ โดยไม่ต้องมีการออกแบบฟีเจอร์ล่วงหน้าได้
การทำ Forward Propagation
Forward Propagation คือ กระบวนการที่ข้อมูลถูกส่งต่อผ่านโครงข่ายประสาทเทียมจากชั้นแรกไปยังชั้นสุดท้ายในแต่ละชั้น
ซึ่งผลลัพธ์จากแต่ละโหนด (node) จะกลายเป็น input ของชั้นถัดไป จนกระทั่งได้ผลลัพธ์สุดท้ายที่ output layer ซึ่งจะถูกนำไปใช้ในการเปรียบเทียบกับค่าจริงเพื่อตรวจสอบความผิดพลาด
Backpropagation และการเรียนรู้ของระบบ
หลังจากได้ผลลัพธ์ในขั้นตอน forward หากค่าที่คาดการณ์ไม่ตรงกับค่าจริง ระบบจะคำนวณความผิดพลาด (error) ผ่าน Loss Function เช่น Mean Squared Error หรือ Cross Entropy แล้วนำกลับไปปรับปรุงโมเดลผ่านกระบวนการที่เรียกว่า Backpropagation โดยขั้นตอนนี้จะประกอบด้วย…
- การคำนวณ gradient ของ error ย้อนกลับไปแต่ละชั้น
- ปรับค่าน้ำหนัก (weights) ให้โมเดลเรียนรู้จากความผิดพลาด
- ทำซ้ำกระบวนการนี้หลายรอบ (epochs) จน error ลดลง
นี่คือกระบวนการที่ทำให้โมเดล Deep Learning เรียนรู้ได้จากข้อมูลด้วยตัวมันเอง
การใช้ข้อมูล BigQuery ในการฝึกสอนโมเดล
Bigquery คือ ระบบฐานข้อมูลแบบคลังข้อมูล (Data Warehouse) ที่รองรับข้อมูลขนาดใหญ่ในรูปแบบ SQL และสามารถเชื่อมต่อกับการเทรน AI ได้โดยตรงผ่านบริการ BigQuery ML โดยผู้ใช้งานสามารถดึงข้อมูลจาก BigQuery มาสร้าง training dataset, ใช้ Machine Learning เบื้องต้นผ่าน SQL หรือส่งต่อไปยังระบบ Deep Learning ที่ซับซ้อนมากขึ้นได้อย่างราบรื่น เพื่อให้โมเดลเรียนรู้จากข้อมูลที่หลากหลายและสอดคล้องกับการใช้งานจริง
การใช้งานผ่าน API Gateway
เมื่อเทรนโมเดลเสร็จแล้ว ขั้นตอนสำคัญคือการนำโมเดลไปใช้งานจริง ซึ่งมักจะเชื่อมต่อผ่านระบบที่เรียกว่า API โดยเฉพาะในระบบขนาดใหญ่ที่มีการใช้งานหลายช่องทาง เช่น เว็บไซต์หรือแอปพลิเคชัน การใช้ API Gateway เป็นจุดกลางที่คอยจัดการคำขอจากผู้ใช้หรือระบบภายนอก ก่อนจะส่งข้อมูลเข้าสู่โมเดล AI และรับผลลัพธ์กลับ เพื่อตอบสนองได้แบบเรียลไทม์ นอกจากนี้ API Gateway ยังช่วยในเรื่องการจัดการสิทธิ์การเข้าถึง (Authorization), รองรับการใช้งานจำนวนมากพร้อมกัน (Scalability) และลดภาระของเซิร์ฟเวอร์ AI ด้วยการทำ Caching ซึ่งเป็นหัวใจของการนำโมเดล Deep Learning ไปใช้งานในระดับ production จริงด้วย
การรันโมเดล AI Deep Learning บน Google Cloud
เราสามารถรันโมเดลของ AI Deep Learning ได้บน Google Cloud คือ หนึ่งในผู้ให้บริการแพลตฟอร์มคลาวด์ที่สนับสนุนการทำงานของ AI และ Deep Learning อย่างเต็มรูปแบบที่องค์กรซึ่งธุรกิจสามารถใช้ Google Cloud เพื่อสร้างระบบ AI ที่มีประสิทธิภาพสูงโดยไม่ต้องลงทุนซื้อเครื่องเซิร์ฟเวอร์เอง
Deep Learning มีกี่ประเภท อะไรบ้าง ?
Deep Learning มีอะไรบ้าง นี่น่าจะเป็นคำถามที่หลายคนอยากรู้เมื่อเริ่มสนใจ AI อย่างจริงจัง เพราะเบื้องหลังเทคโนโลยีที่คุณใช้ทุกวัน ตั้งแต่ SearchGPT ไปจนถึงระบบแปลภาษา ล้วนพัฒนามาจากโมเดล Deep Learning หลายรูปแบบที่แตกต่างกันตามวัตถุประสงค์
ในหัวข้อนี้เราจึงจะพาคุณไปสำรวจประเภทของ Deep Learning ที่ถูกใช้งานจริง ทั้งในระดับวิจัยและใน Deep Learning ในชีวิตประจําวัน
Convolutional Neural Networks (CNN)

Convolutional Neural Networks (CNN) คือ สถาปัตยกรรมของ Deep Learning ที่ออกแบบมาเพื่อประมวลผลข้อมูลภาพโดยเฉพาะ เช่น รูปภาพ วิดีโอ ภาพทางการแพทย์ ฯลฯ โดย CNN มีความสามารถพิเศษในการตรวจจับ spatial features ได้อย่างแม่นยำ โดยมีเบื้องหลังการทำงานดังนี้
- Input Layer : เริ่มจากการป้อนภาพ เช่น รูปม้าลาย (zebra) เข้าระบบ โดยมี Kernel หรือ Filter คอยสแกนแต่ละจุดในภาพ เพื่อหา pattern ต่างๆ
- Convolution + ReLU Layers: ระบบจะทำ Convolution เพื่อสกัดลักษณะเด่น เช่น ขอบ เส้น หรือพื้นผิว และใช้ ReLU (Rectified Linear Unit) เป็น Activation Function เพื่อเพิ่ม non-linearity
- Pooling Layer: แต่ละรอบจะตามด้วย Pooling เช่น Max Pooling เพื่อลดขนาดภาพ ทำให้ระบบเร็วขึ้นโดยไม่เสียข้อมูลสำคัญไป
- Flatten Layer: เมื่อนำข้อมูลมารวมเป็นเวกเตอร์ 1 มิติ จะผ่านไปยัง Fully Connected Layer เพื่อวิเคราะห์ความสัมพันธ์เชิงลึก
- Fully Connected Layer: เหมือนโครงข่ายประสาทเทียมทั่วไป เป็นส่วนที่เรียนรู้จากฟีเจอร์ที่ได้มา
- Output Layer สุดท้ายใช้ Softmax Activation Function เพื่อให้โมเดลแจกแจงผลลัพธ์เป็นความน่าจะเป็น เช่น 0.7 → Zebra, 0.2 → Horse, 0.1 → Dog
ด้วยเหตุนี้ CNN จึงสามารถแยกแยะวัตถุในภาพได้อย่างแม่นยำ โดยไม่ต้องออกแบบกฎการจำแนกเอง ช่วยลดความซับซ้อนของข้อมูล โดยไม่ทำให้คุณลักษณะสำคัญหายไป รวมถึงเทรนเร็วกว่าโมเดลทั่วไป และใช้งานได้หลากหลาย
อย่างไรก็ตาม CNN อาจไม่เหมาะกับข้อมูลลำดับ เช่น การประมวลผลภาษา และไวต่อความเปลี่ยนแปลงเล็กน้อยของภาพ เช่น ความเอียงหรือแสงที่ต้องการข้อมูลจำนวนมากและใช้พลังประมวลผลสูง เป็นต้น
Recurrent Neural Networks (RNN)

Recurrent Neural Networks (RNN) คือสถาปัตยกรรม Deep Learning ที่ออกแบบมาเพื่อจัดการกับ Sequential Data เช่น ข้อความ เสียง ดนตรี ข้อมูลที่เปลี่ยนแปลงตามเวลา (Time Series) ฯลฯ
โดยจุดเด่นของ RNN คือ ความสามารถในการจดจำสถานะก่อนหน้า และนำมาใช้กับการประมวลผลในขั้นตอนถัดไป ทำให้เหมาะอย่างยิ่งกับงานที่ต้องเข้าใจบริบทต่อเนื่อง เช่น การพยากรณ์คำถัดไป การแปลภาษา ฯลฯ ซึ่งโครงสร้างของ RNN จะมีลำดับการทำงาน ดังนี้
- Input Layer: รับข้อมูลทีละตำแหน่งในลำดับ เช่น ตัวอักษรหรือคำในประโยค
- Hidden Layer (พร้อม Recurrence): เก็บสถานะของข้อมูลก่อนหน้าไว้ในหน่วยความจำ เพื่อใช้อ้างอิงกับ input ถัดไป
- Output Layer: ให้ผลลัพธ์ตามข้อมูลและบริบทที่สะสม เช่น คำถัดไปในข้อความ ค่าพยากรณ์ในลำดับเวลา
ส่วนข้อจำกัดอาจจะเทรนช้า และทำงานแบบลำดับ (Sequential Processing) ไม่สามารถทำแบบขนาน (Parallelize) ได้ดี ซึ่งปัจจุบันหลายงานถูกแทนที่ด้วย Transformer Models เช่น GPT, BERT, SearchGPT เพราะจัดการกับบริบทยาวๆ ได้ดีกว่า
Generative Adversarial Networks (GANs)

Generative Adversarial Networks (GANs) คือ สถาปัตยกรรม Deep Learning ที่ออกแบบมาเพื่อสร้างข้อมูลใหม่ที่เหมือนจริง โดยเรียนรู้จากข้อมูลต้นฉบับ ตัวอย่างเช่น ภาพใบหน้าที่ไม่เคยมีอยู่จริง, เสียงพูดจำลอง, วิดีโอ, ข้อความ ฯลฯ ส่วนใหญ่ใช้ในงาน Data Augmentation โดยเฉพาะเมื่อมีข้อมูลจริงน้อย พร้อมทั้งสร้าง AI Art, Face Swap หรือ Style Transfer ได้อย่างแม่นยำ
โครงสร้างของ GAN ประกอบด้วยโมเดลย่อย 2 ส่วนที่ทำงานแบบแข่งขันกัน ได้แก่
- Generator (ผู้สร้าง): ทำหน้าที่สร้างข้อมูลจำลองจาก noise หรือข้อมูลสุ่ม เช่น ภาพปลอมที่ดูเหมือนจริง
- Discriminator (ผู้ตรวจจับ): ทำหน้าที่ตรวจสอบว่าข้อมูลที่ได้รับมานั้นของจริง (จาก dataset) หรือ ของปลอม (จาก Generator)
ซึ่งกระบวนการฝึกจะเกิดขึ้นแบบวนซ้ำ โดยที่Generator จะพยายามหลอก Discriminator ว่าข้อมูลปลอมคือของจริง ส่วน Discriminator จะเรียนรู้เพื่อแยกแยะของปลอมออกจากของจริงให้แม่นขึ้น จนกระทั่ง Generator สามารถสร้างข้อมูลที่หลอก Discriminator ได้สำเร็จ
สำหรับข้อจำกัดของการฝึกโมเดลนั้นคือ อาจจะไม่เสถียร และต้องบาลานซ์ Generator กับ Discriminator อย่างระมัดด้วยความระมัดระวัง รวมถึงต้องการทรัพยากรสูงในการประมวลผล โดยเฉพาะงานวิดีโอคุณภาพสูง และอาจถูกใช้ในทางที่ไม่เหมาะสม เช่น การสร้าง Deepfake หรือสื่อปลอมได้
Autoencoders

Autoencoders คือ สถาปัตยกรรมของ Deep Learning ที่ถออกแบบมาเพื่อบีบอัด (compress) ข้อมูลให้เหลือเฉพาะข้อมูลที่สำคัญ แล้วสร้างข้อมูลนั้นกลับขึ้นมาใหม่ให้ใกล้เคียงต้นฉบับที่สุด โดยไม่ต้องใช้ข้อมูลกำกับ (Unsupervised Learning) ดังนั้น Autoencoders จึงมักใช้ในงานด้านการลดมิติข้อมูล (Dimensionality Reduction), ลบสัญญาณรบกวน (Denoising), ตรวจจับความผิดปกติ (Anomaly Detection) และกู้คืนข้อมูลที่สูญเสียไป เช่น ภาพที่เบลอหรือข้อมูลที่ขาดหาย เป็นต้น
สำหรับโครงสร้างของ Autoencoder แบ่งออกเป็น 3 ส่วนหลัก คือ
- Encoder ทำหน้าที่แปลงข้อมูลขาเข้า (Input) เช่น รูปภาพให้กลายเป็นเวกเตอร์ขนาดเล็กลง
- Latent Space (Bottleneck) เป็นส่วนกลางที่เก็บข้อมูลในรูปแบบที่ถูกบีบอัด ซึ่งแสดงถึงสิ่งสำคัญของข้อมูล
- Decoder ทำหน้าที่สร้างข้อมูลกลับขึ้นมาใหม่จาก Latent Space ให้ใกล้เคียงกับ Input เดิมมากที่สุด
ส่วนข้อจำกัดผลลัพธ์ที่สร้างอาจเบลอหรือไม่สมบูรณ์ หากข้อมูลซับซ้อนเกินไป จึงไม่เหมาะกับการสร้างข้อมูลใหม่จากศูนย์แบบที่ GAN ทำได้ และถ้าหากเลือกขนาด Latent Space ไม่เหมาะสม อาจทำให้ข้อมูลสำคัญสูญหายได้
Transformer Models

Transformer Models คือ สถาปัตยกรรมของ Deep Learning ที่ออกแบบมาเพื่อประมวลผลข้อมูลประเภทลำดับ (Sequence Data) เช่น ข้อความ ภาษา หรือรหัสโปรแกรม โดยไม่ต้องพึ่งโครงสร้างลูปแบบเดิมอย่าง RNN ซึ่งต้องประมวลผลทีละขั้นตอน
ความโดดเด่นของ Transformer คือการใช้กลไกที่เรียกว่า Self-Attention ซึ่งช่วยให้โมเดลสามารถให้ความสำคัญกับทุกคำในลำดับข้อมูลได้พร้อมกันในคราวเดียว ทำให้เข้าใจบริบทได้ดีขึ้น และรองรับการประมวลผลแบบขนาน (Parallelization) ซึ่งเหมาะสำหรับการฝึกโมเดลขนาดใหญ่
ส่วนด้านข้อจำกัดของ Transformer Models คือ ต้องใช้พลังประมวลผลและหน่วยความจำสูงมาก โดยเฉพาะกับโมเดลขนาดใหญ่ และต้องการข้อมูลฝึกจำนวนมากเพื่อให้ได้ผลลัพธ์ที่แม่นยำ ถึงแม้จะเข้าใจบริบทได้ดี แต่ก็ยังไม่สามารถทำเหตุผลเชิงลึกได้เทียบเท่ามนุษย์
ข้อดีและข้อจำกัดของ Deep Learning
ในยุคที่ธุรกิจต้องตัดสินใจบนพื้นฐานของข้อมูลขนาดใหญ่ Deep Learning ได้กลายเป็นเครื่องมือทรงพลังในการสร้างโมเดลอัจฉริยะ ทั้งในด้านการเข้าใจภาษา การจดจำภาพ และการทำนายพฤติกรรมผู้ใช้ อย่างไรก็ตาม ก่อนนำไปใช้งานจริงในธุรกิจควรเข้าใจทั้งข้อดีและข้อจำกัด เพื่อวางแผนการใช้งานได้อย่างมีประสิทธิภาพ
ข้อดีของ Deep Learning
- มีความแม่นยำสูง โดยเฉพาะในงานที่มีข้อมูลจำนวนมาก เช่น ภาพ เสียง ภาษา ฯลฯ
- เรียนรู้จากข้อมูลได้เอง โดยไม่ต้องพึ่ง Feature Engineering แบบเดิม
- รองรับข้อมูลไม่มีโครงสร้าง (Unstructured Data) ได้ดี เช่น รูปภาพ ข้อความ วิดีโอ
- เหมาะกับงานที่มีความซับซ้อนสูง เช่น Chatbot, Recommendation, Fraud Detection ฯลฯ
- สามารถต่อยอดกับโมเดลสำเร็จรูป (Pre-trained Models) เช่น GPT, BERT, Gemini ได้
- เรียนรู้ต่อเนื่องได้ดีขึ้นเรื่อยๆ เมื่อมีข้อมูลมากขึ้น (Scalability & Performance Boost)
ข้อจำกัดของ Deep Learning
- ต้องใช้ข้อมูลจำนวนมาก หากข้อมูลน้อย โมเดลจะไม่แม่นยำหรือ Overfit ได้ง่าย
- ต้องใช้ทรัพยากรสูง เช่น GPU / TPU และหน่วยความจำขนาดใหญ่
- ไม่อธิบายการตัดสินใจว่ามีที่มาจากไหน ทำให้ตรวจสอบยาก
- ใช้เวลาฝึกนาน โดยเฉพาะโมเดลขนาดใหญ่หรือชุดข้อมูลที่ซับซ้อน
- ต้องการทีมงานเฉพาะทาง ทั้งด้าน Data Science, MLOps และ AI Engineering ในการทำและดูแล
สรุปภาพรวม Deep Learning คืออะไร
จากบทความนี้ เราได้ทำความเข้าใจว่า Deep Learning คือเทคโนโลยีเบื้องหลังความสามารถของ AI ในยุคปัจจุบัน ไม่ว่าจะเป็นการจำใบหน้า ระบบแนะนำสินค้า หรือแม้แต่โมเดลภาษาขนาดใหญ่ เช่น ChatGPT, Gemini ของ Google เป็นต้น
ในทางปฏิบัติ Deep Learning ถูกนำไปใช้ผ่านโมเดลหลากหลายรูปแบบ เช่น CNN, RNN, GANs, Autoencoders และ Transformers โดยมีจุดแข็งที่สำคัญคือความสามารถในการเรียนรู้จากข้อมูลดิบโดยไม่ต้องเขียนกฎตายตัว รวมถึงการประมวลผลข้อมูลไม่มีโครงสร้าง (Unstructured Data) ได้อย่างแม่นยำ
อย่างไรก็ตาม Deep Learning ยังมีข้อจำกัดที่ควรพิจารณา เช่น การใช้ทรัพยากรสูง ความซับซ้อนในการฝึกโมเดล ความยากในการอธิบายการตัดสินใจของระบบ (Explainability) เป็นต้น
















